Hi 👋
I am a CNRS Research Scientist at CerCo (Toulouse) working at the interface of artificial intelligence and computational neuroscience. My research asks a simple question: how does the brain generalize so well from so little data? My working hypothesis is that the brain implements an internal generative model of the world. Intuitively, a generative model is like a simulator that captures the rules that produce the data. If you know the rules—not just a list of past examples—you can imagine plausible new cases and predict what you haven’t seen yet (e.g., recognize an object from a new viewpoint after seeing it once). To test this hypothesis, I (1) develop mathematical theories of how the brain processes information; (2) implement these theories as deep learning models—especially generative models; and (3) evaluate them against behavioral and neural data. I earned my PhD at the Institute of Neuroscience of Marseille under the supervision of Laurent U Perrinet. Then I completed a post-doc with Thomas Serre at ANITI (Toulouse, France) & Brown University (Providence, USA). My long-term goal is to reverse-engineer the computations of cognition.

Main research articles
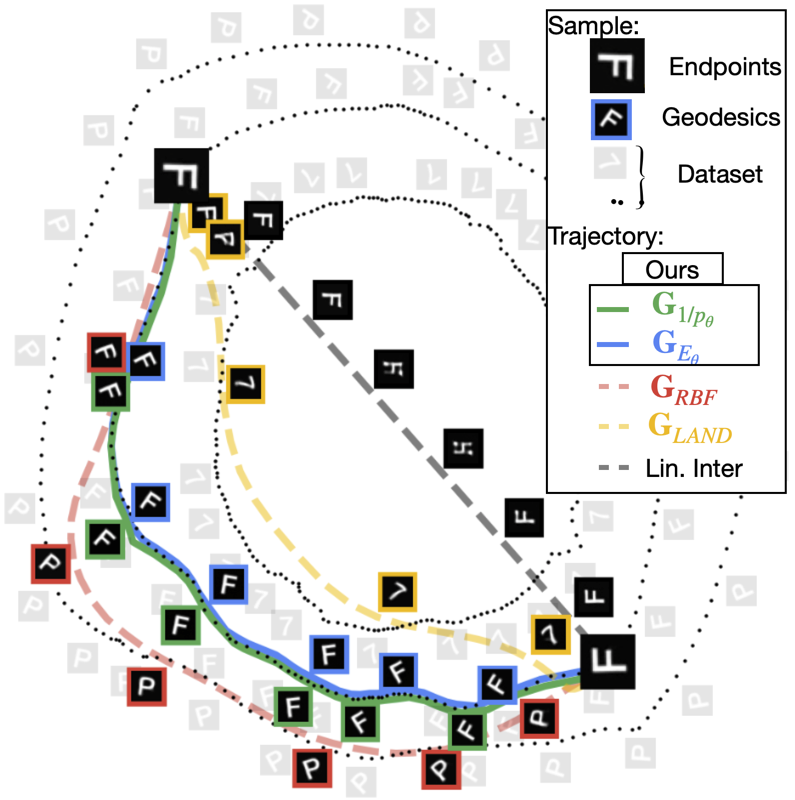
In this work, we propose a method for deriving Riemannian metrics directly from pretrained Energy-Based Models (EBMs)—a class of generative models that assign low energy to high-density regions. These metrics define spatially varying distances, enabling the computation of geodesics—shortest paths that follow the data manifold's intrinsic geometry. Our work is the first to derive Riemannian metrics from EBMs, enabling data-aware geodesics and unlocking scalable, geometry-driven learning for generative modeling and simulation.

Humans can effortlessly draw new categories from a single exemplar, a feat that has long posed a challenge for generative models. Here, we study how different inductive biases shape the latent space of Latent Diffusion Models (LDMs). We demonstrate that LDMs with redundancy reduction and prototype-based regularizations produce near-human-like drawings (regarding both samples' recognizability and originality) —better mimicking human perception (as evaluated psychophysically). Overall, our results suggest that the gap between humans and machines in one-shot drawings is almost closed.
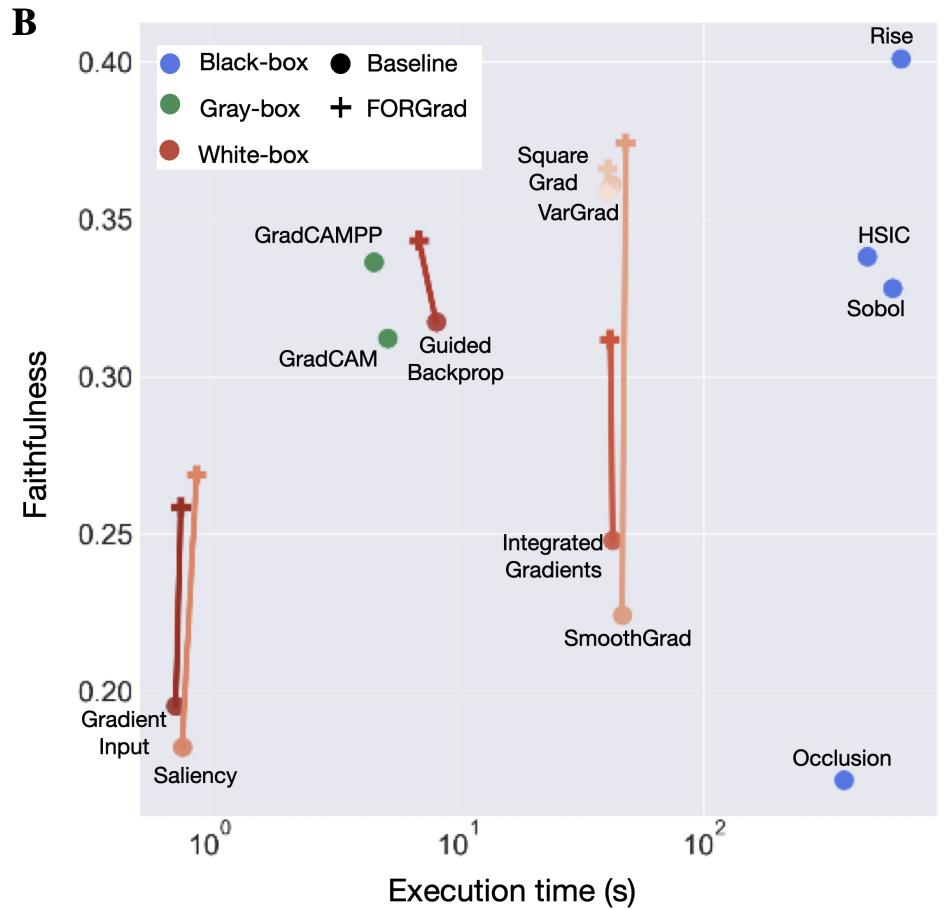
Attribution methods explain model decisions by scoring input contributions. We show efficient “white-box” methods use gradients polluted by high-frequency artifacts. FORGrad—a simple Fourier low-pass filter with architecture-specific cutoffs—cleans these gradients. Across models, it consistently boosts white-box faithfulness, making them competitive with costlier black-box approaches while staying lightweight.
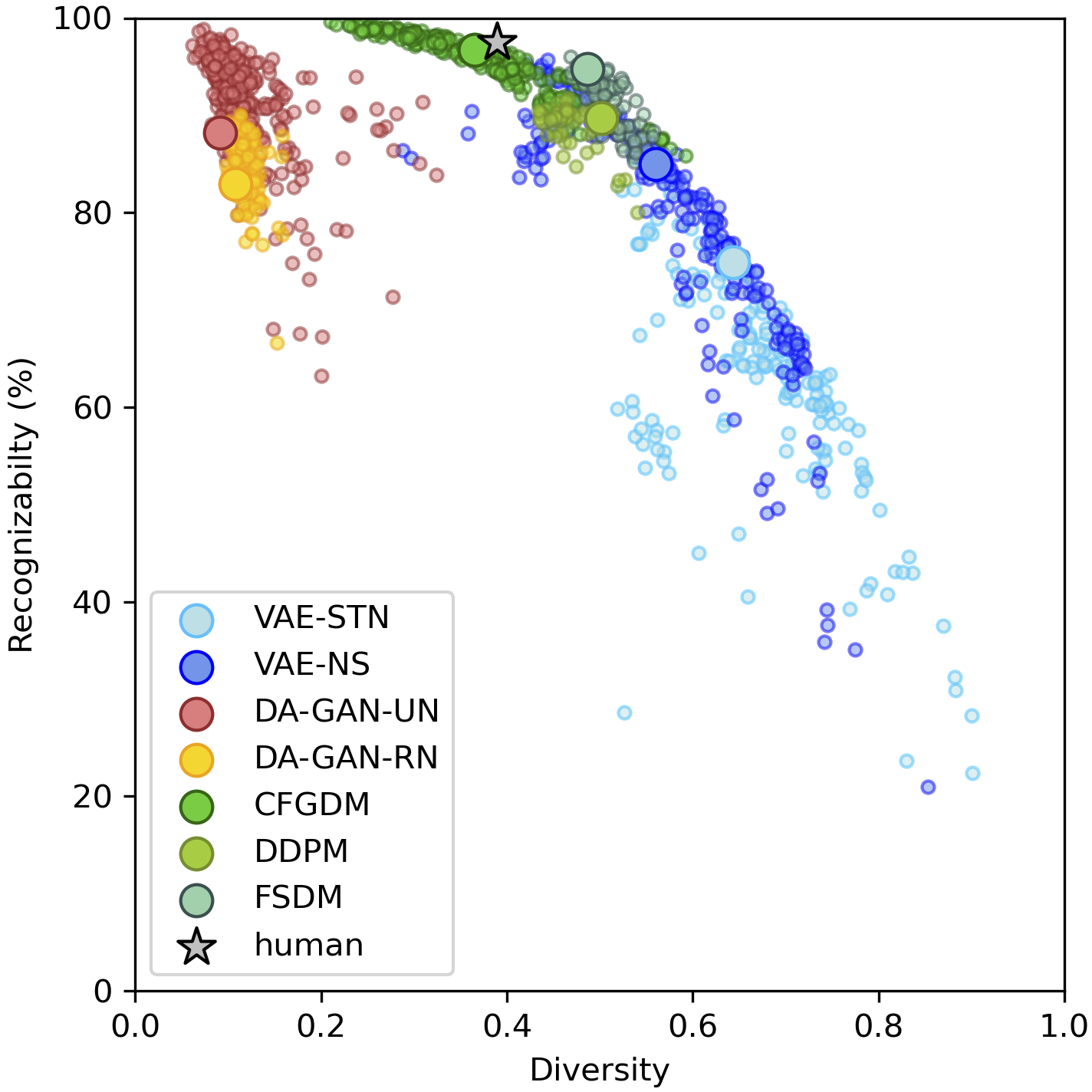
An important milestone for AI is the development of algorithms that can produce drawings that are indistinguishable from those of humans. Here, we adapt the 'diversity vs. recognizability' scoring framework from Boutin et al, 2022 and find that one-shot diffusion models have indeed started to close the gap between humans and machines. However, comparing human category diagnostic features, collected through an online psychophysics experiment, against those derived from diffusion models reveals that humans rely on fewer and more localized features. Overall, our study suggests that diffusion models have significantly helped improve the quality of machine-generated drawings; however, a gap between humans and machines remains.
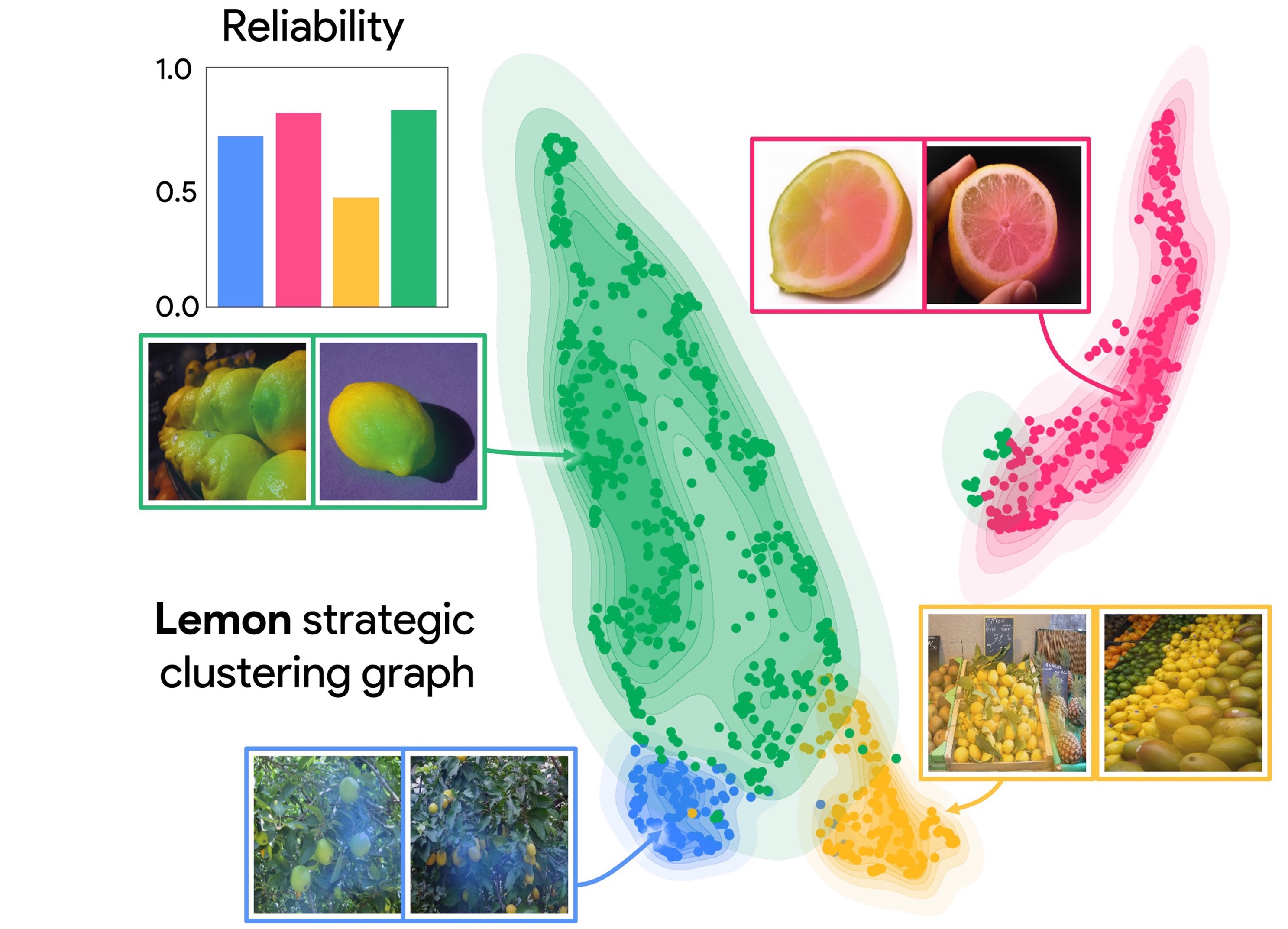
In this article we demonstrate that all concept extraction methods can be viewed as dictionary learning methods. We leverage this common framework to develop a comprehensive framework for comparing and i mproving concept extraction methods. Furthermore, we extensively investigate the estimation of concept importance and show that it is possible to determine optimal importance estimation formulas in certain cases. We also highlight the significance of local concept importance in addressing a crucial question in Explainable Artificial Intelligence (XAI): identifying data points classified based on similar reasons.

Since the remarkable work of Chris Olah and the Clarity team at OpenAI, feature visualization techniques have stagnated since 2017, and the methods proposed at the time are very difficult to make work on modern models (e.g. Vision Transformers). In this article, we propose a simple technique to revive feature visualization on modern models. Our method is based on a magnitude constraint, which ensures that the generated images have a magnitude similar to real images while avoiding the need for managing an additional hyperparameter.
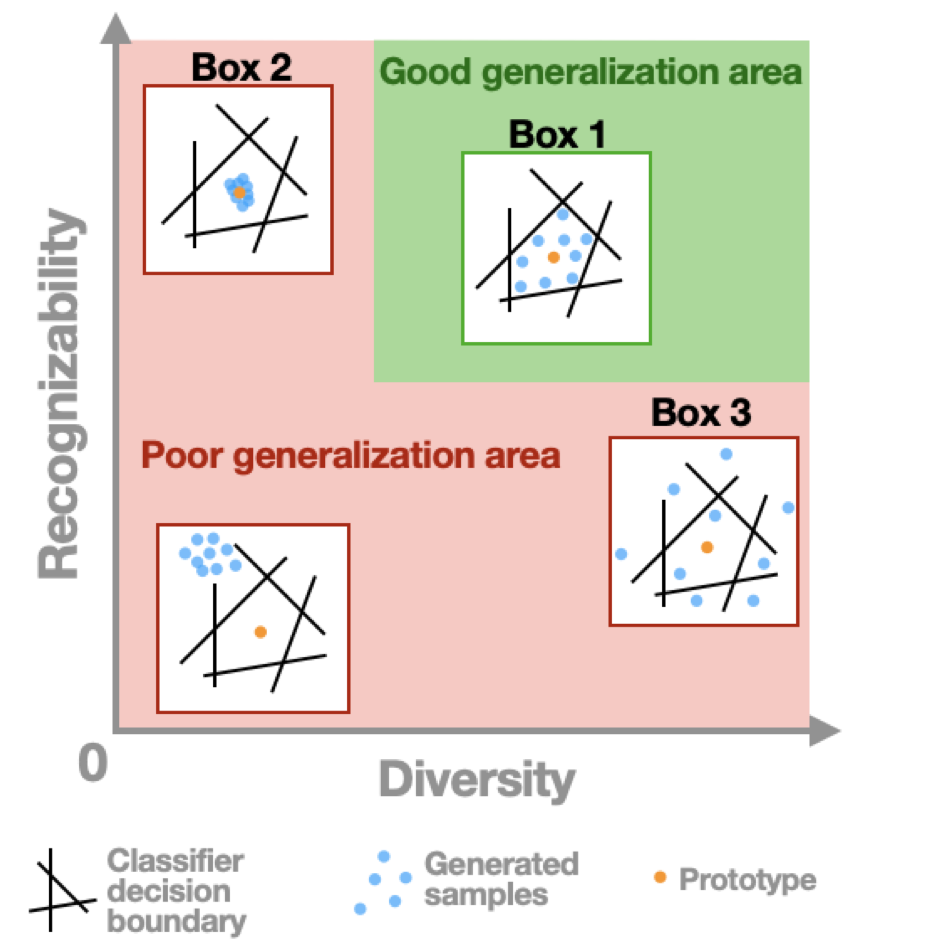
Here, we propose a new framework to evaluate one-shot generative models along two axes: sample recognizability vs. diversity (ie, intra-class variability). Using this framework, we perform a systematic evaluation of representative one-shot generative models on the Omniglot handwritten dataset. We show that GAN-like and VAE-like models fall on opposite ends of the diversity-recognizability space. Using the diversity-recognizability framework, we were able to identify models and parameters that closely approximate human data.
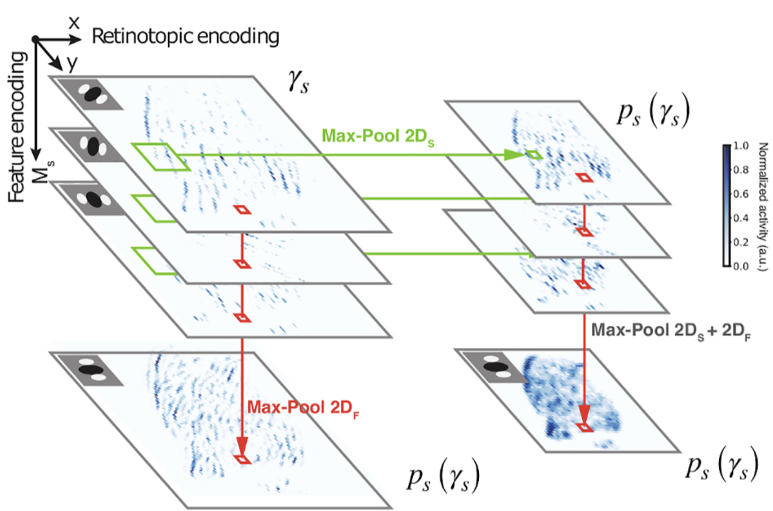
V1 neurons are orientation-selective with varying phase selectivity (simple → complex). Prior models tie phase invariance to orientation maps in higher mammals but can’t explain complex cells in species without maps. Using a convolutional Sparse Deep Predictive Coding (SDPC) model, we show a single mechanism—pooling—accounts for both: pooling in feature space drives orientation map formation, while pooling in retinotopic space yields complex-cell invariance. SDPC thus explains complex cells with or without orientation maps and offers a unified account of V1’s structural and functional diversity.
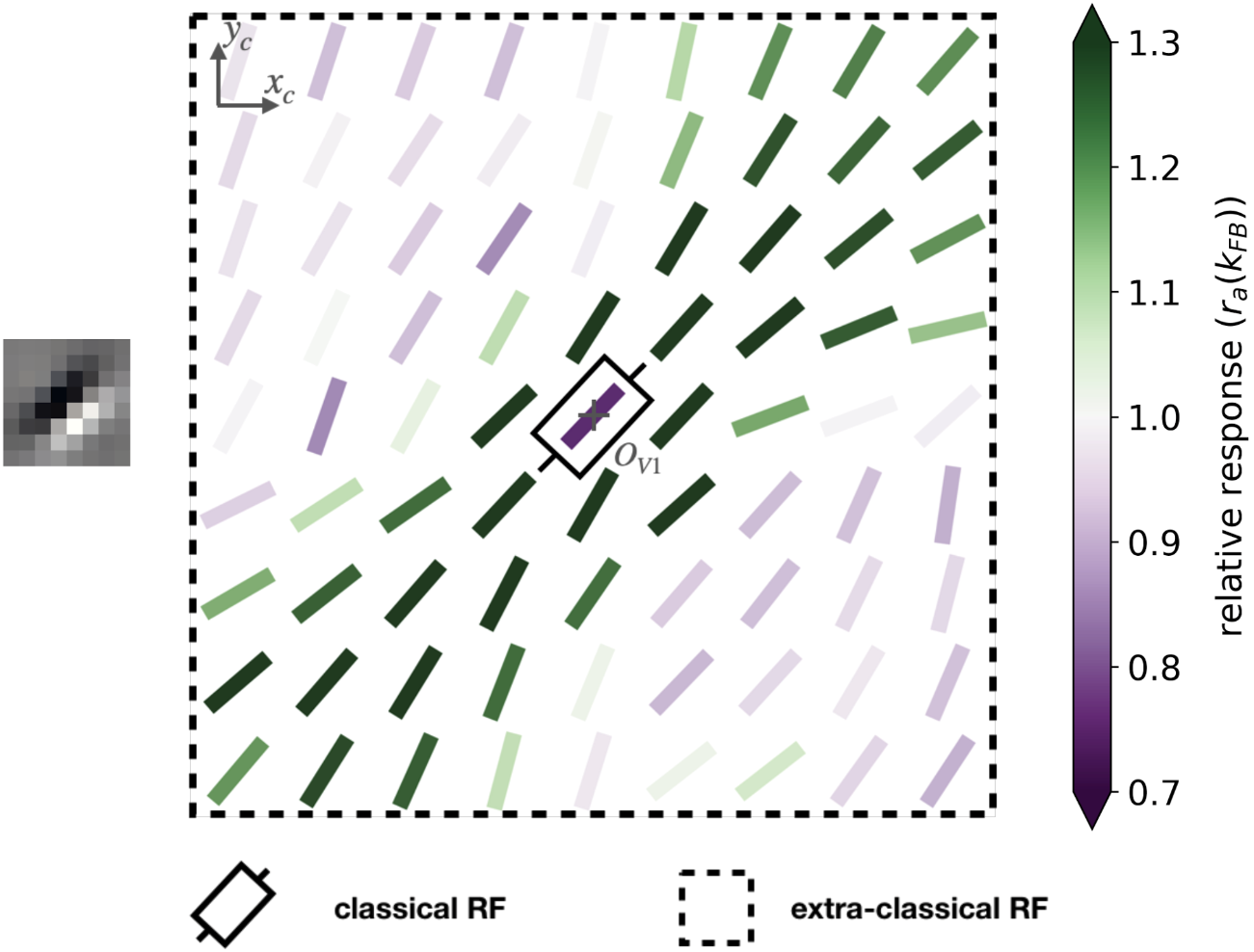
Recurrent/feedback connections shape context in early vision, but most models split neural vs. representational effects. Sparse Deep Predictive Coding (SDPC) unifies them: Sparse Coding handles intralayer recurrence; Predictive Coding mediates interlayer feedforward/feedback in a hierarchical convnet. Trained as a 2-layer V1/V2 proxy, SDPC learns V1-like oriented RFs and more complex V2 features; feedback reorganizes V1 interaction maps (association fields/“good continuation”), promoting contour integration. The same feedback boosts robustness to noise/blur and improves reconstructions—linking neural- and representation-level feedback in one model.
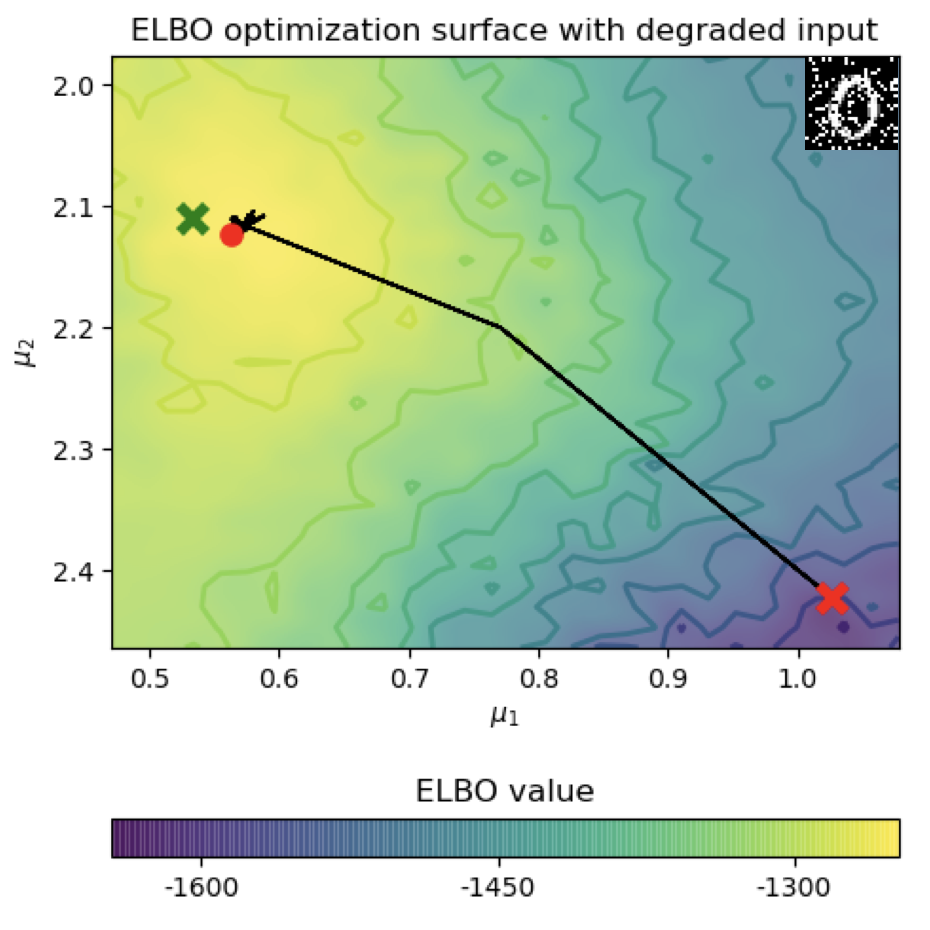
Primate vision generalizes to novel degradations. We link predictive coding networks (PCNs) to variational autoencoders (VAEs), deriving a formal correspondence. This motivates iterative VAEs (iVAEs) as a variational counterpart to PCNs. iVAEs show markedly better OOD generalization than PCNs and standard VAEs. We also introduce a per-sample recognizability metric testable via psychophysics, positioning iVAEs as a promising neuroscience model.
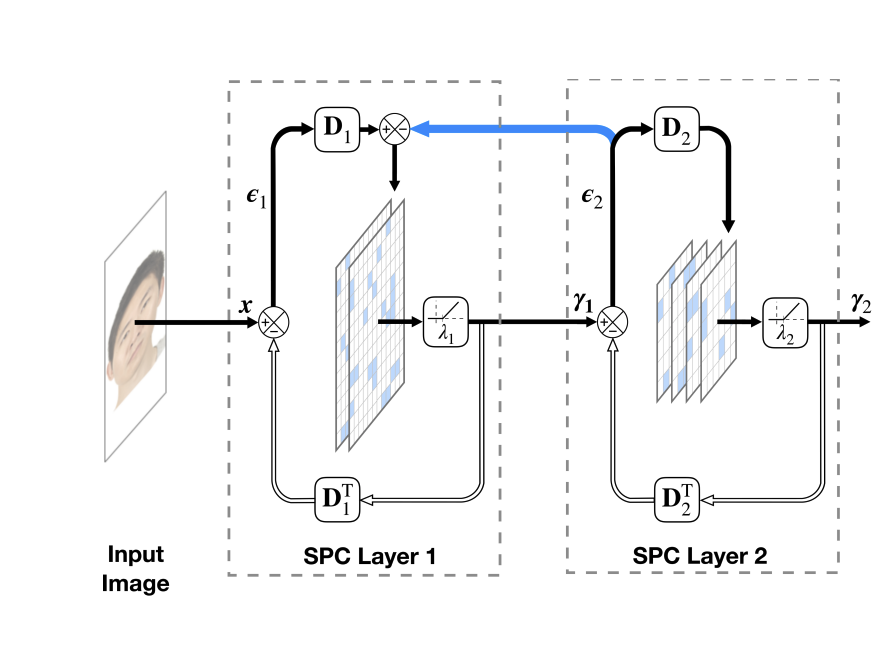
Hierarchical sparse coding (HSC) is often solved layer-wise, but neuroscience suggests adding top-down feedback (predictive coding). We introduce a two-layer sparse predictive coding model (2L-SPC) and compare it to a two-layer hierarchical Lasso (Hi-La). Across four datasets, 2L-SPC transfers error between layers, yielding lower prediction error, faster inference, and better second-layer representations. It also speeds learning and discovers more generic, larger-extent features.